Supply Chain Graph from package-lock.json (LadybugDB)
• Engineering
Embedded graph databases let you query graph-structured data without running a server, managing ports, or dealing with much configuration. They run as a single binary and store the database in one file on disk. That makes them ideal for local analysis, air-gapped environments, or any situation where you want a self-contained tool you can spin up quickly.
LadybugDB, a recently introduced embedded graph database, was used in this experiment to load and explore the dependency graph from a Node.js package-lock.json file.
Background on LadybugDB
LadybugDB continues development from the KuzuDB codebase. KuzuDB, an MIT-licensed open-source embedded graph database, was first released in November 2022 based on research from the University of Waterloo, Canada. It was maintained by Kùzu Inc. (Toronto) and offered features including full-text search, vector indexes, parallel query execution, and WebAssembly support for browser-based usage.
In October 2025, Kùzu Inc. archived the main KuzuDB GitHub repository and stated that “Kuzu is working on something new.” The project website’s documentation and blog posts were moved to GitHub.
Following the archiving:
- Kineviz created a fork named Bighorn and invited community participation to maintain and evolve the codebase.
- Arun Sharma announced LadybugDB as the next step forward, describing it as an effort to build “the DuckDB for graphs.” Sharma serves as project lead, focusing on development and lakehouse-style architecture. He has prior experience contributing to the Linux kernel and working in infrastructure engineering.
LadybugDB’s stated early priorities are:
- Stabilizing the codebase and storage engine
- Fixing bugs, with immediate attention to any security-related issues
- Adding lakehouse capabilities, including the ability to create tables directly over object storage without a separate ingestion step
Sharma has emphasized transparent governance and community involvement. Early investor interest has been reported to support faster development and long-term sustainability.
The graph visualization and client tool G.V() already provides support for LadybugDB (building directly on its prior KuzuDB integration) and was used to visualize and explore the loaded graph in this experiment.
Experiment: Loading a package-lock.json
A package-lock.json file (v2 or v3 format) was chosen because it contains a complete, resolved dependency tree — often thousands of packages deep — that is frequently examined during vulnerability investigations or supply-chain reviews.
A short Python script parses the lockfile and generates:
packages.csv— node datadepends.csv— edge dataload.sql— schema creation andCOPYstatements
Installing LadybugDB is straightforward.
brew install ladybug
To create a database, you can just run:
lbug dbname.bug
From there, you can run the generated load.sql file to create tables and import CSVs. The graph loads in seconds for typical application lockfiles.
Schema
CREATE NODE TABLE Package(
path STRING PRIMARY KEY,
name STRING,
version STRING,
is_dev BOOL,
is_optional BOOL,
is_peer BOOL,
integrity STRING,
resolved STRING
);
CREATE REL TABLE DEPENDS_ON(
FROM Package TO Package,
dep_type STRING,
is_optional BOOL,
is_dev BOOL,
is_peer BOOL
);
path— lockfile package key (used as primary key)- Booleans (
is_dev,is_optional,is_peer) preserve dependency category information integrityandresolvedretain hash and resolution metadata
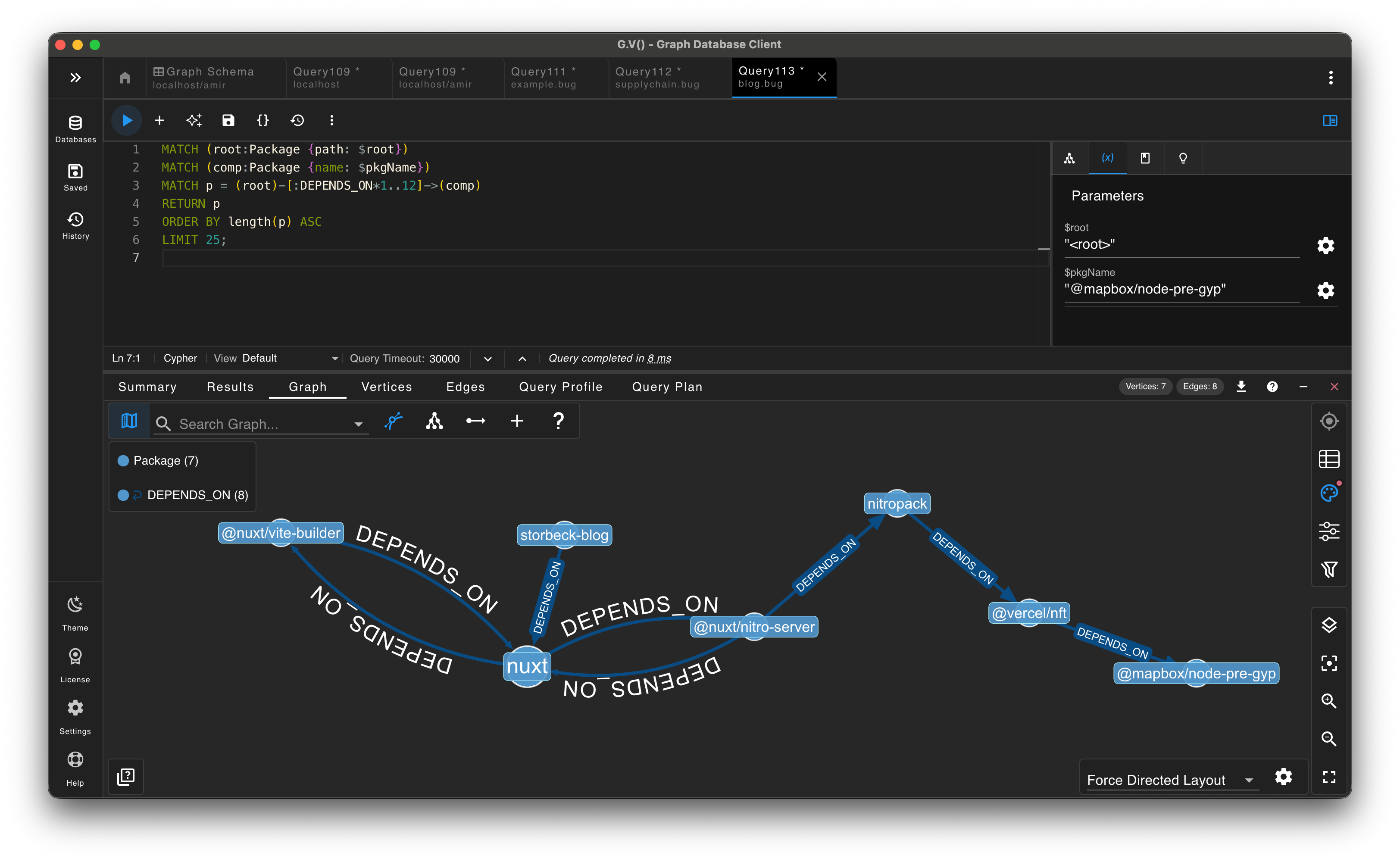
What This Looks Like
The full dependency graph is dense, but even at a glance it shows hubs and hotspots where risk clusters. G.V() makes it easy to pan, filter, and explore the shape of the graph without losing context.
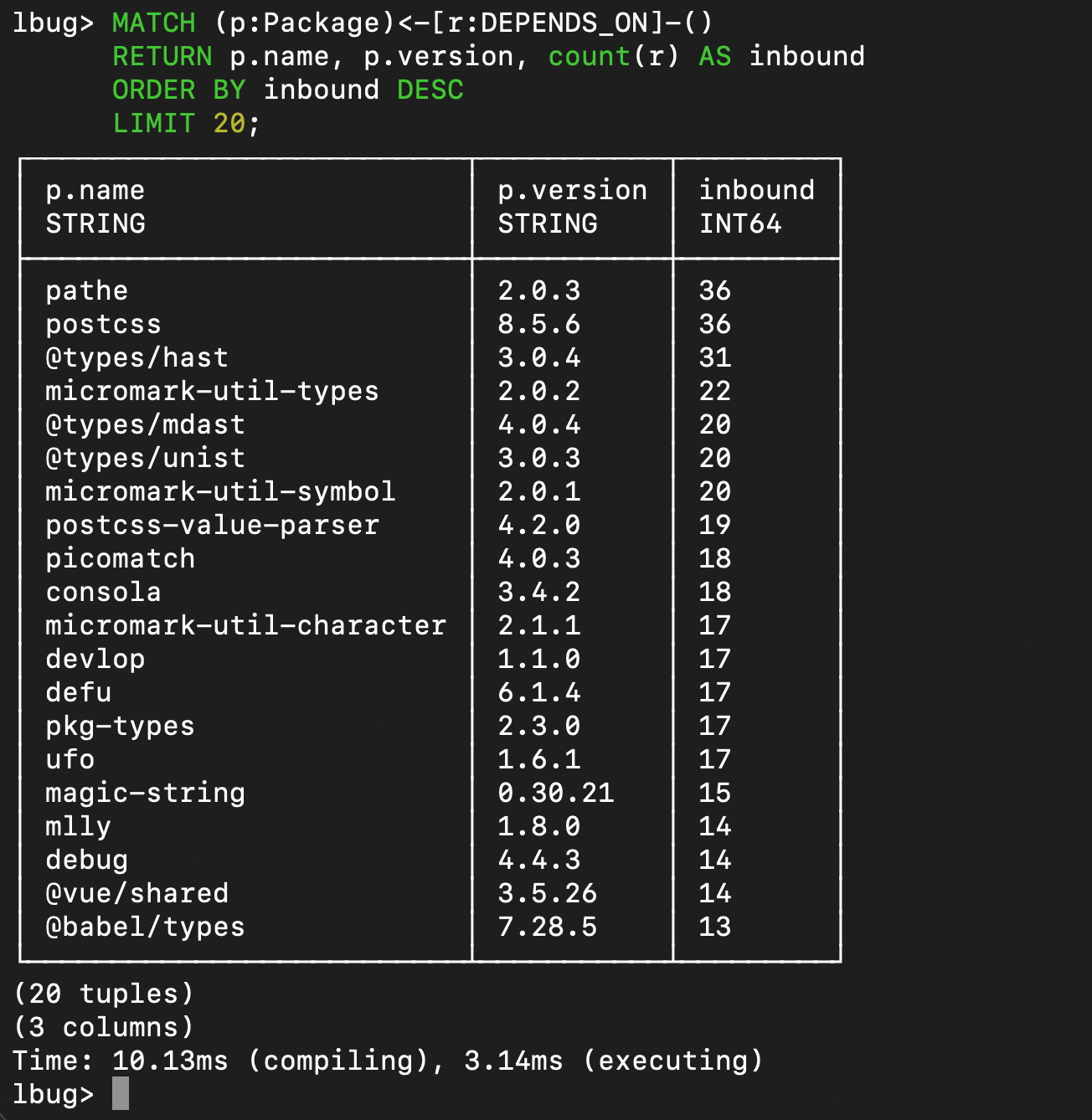
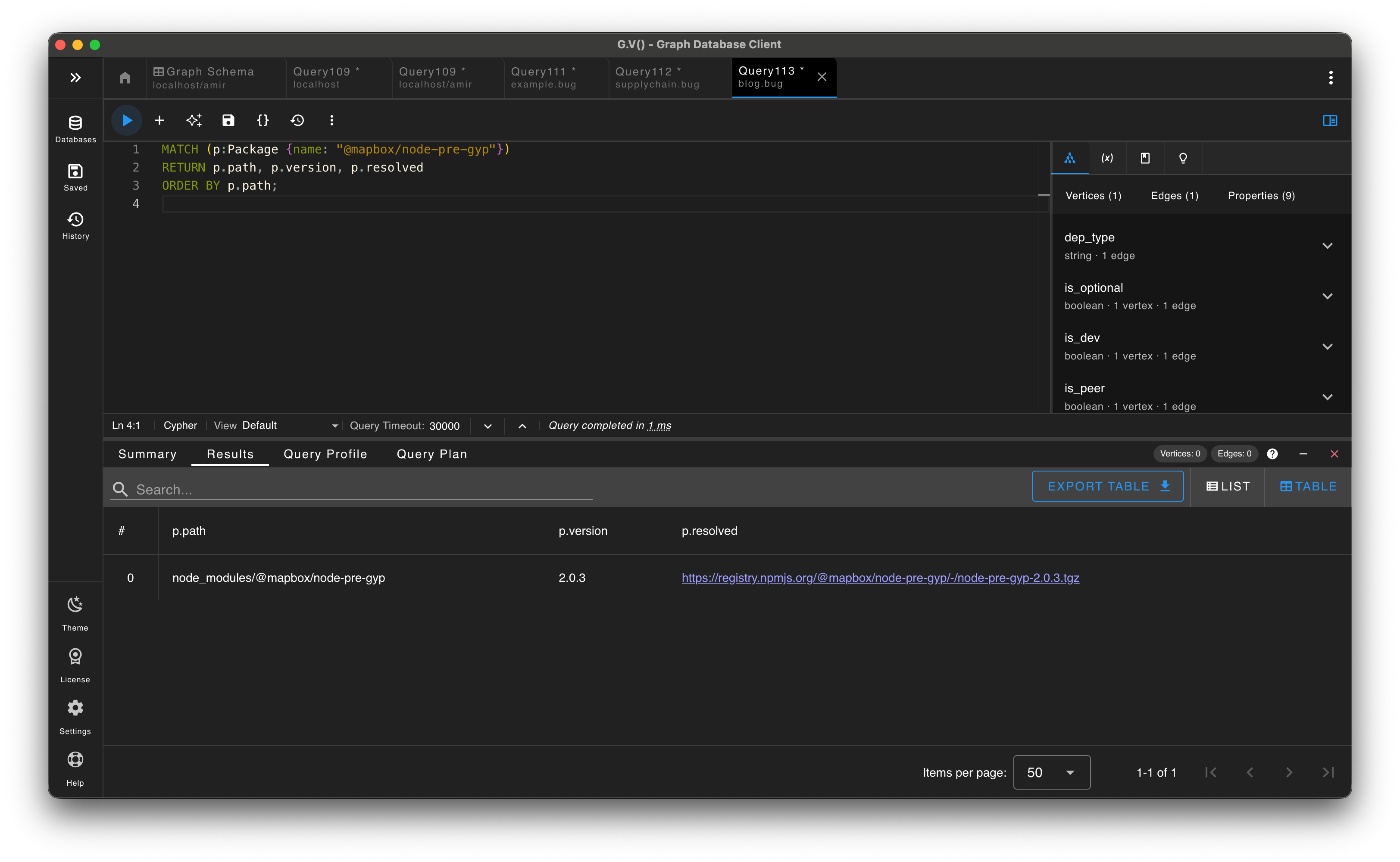
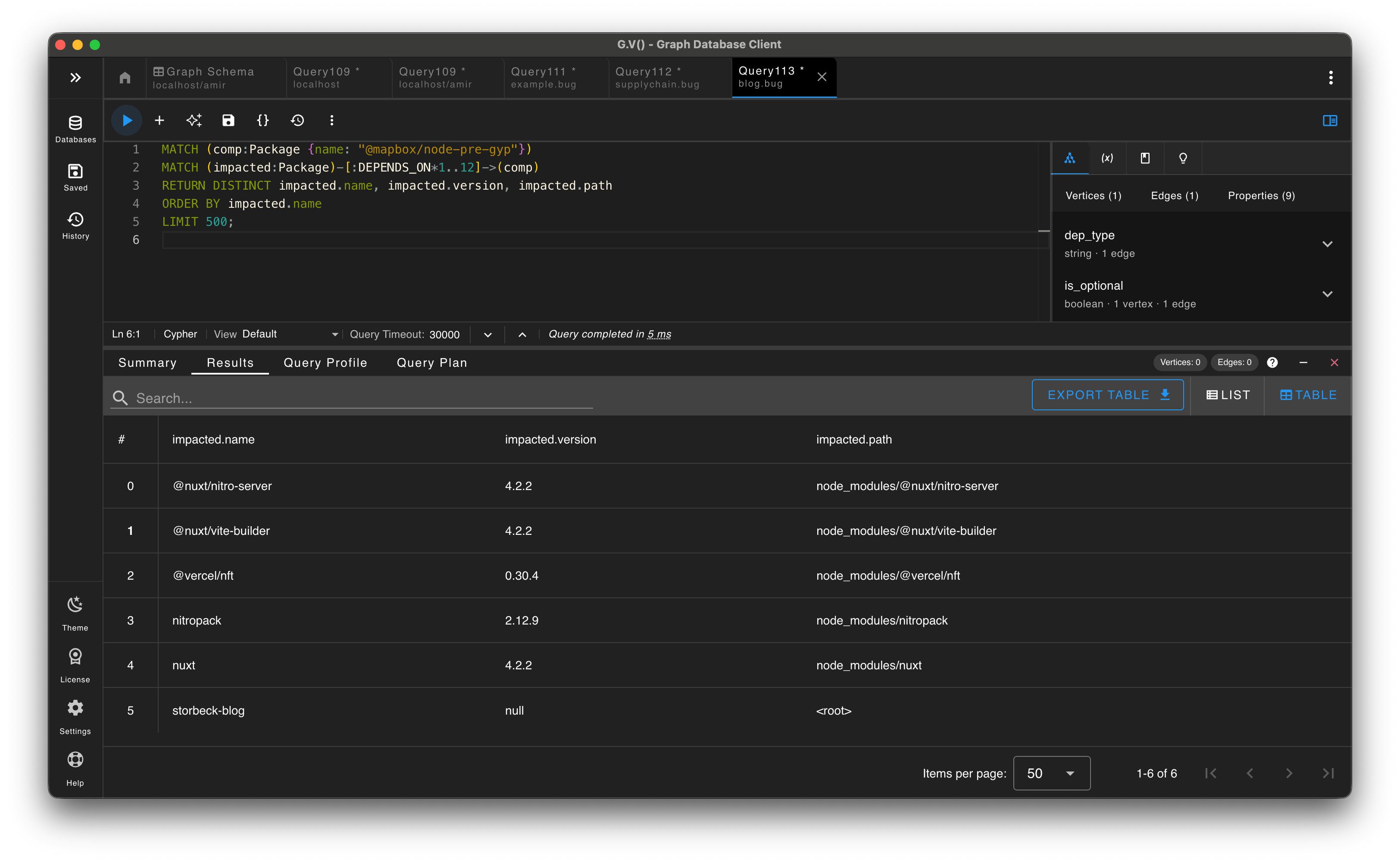
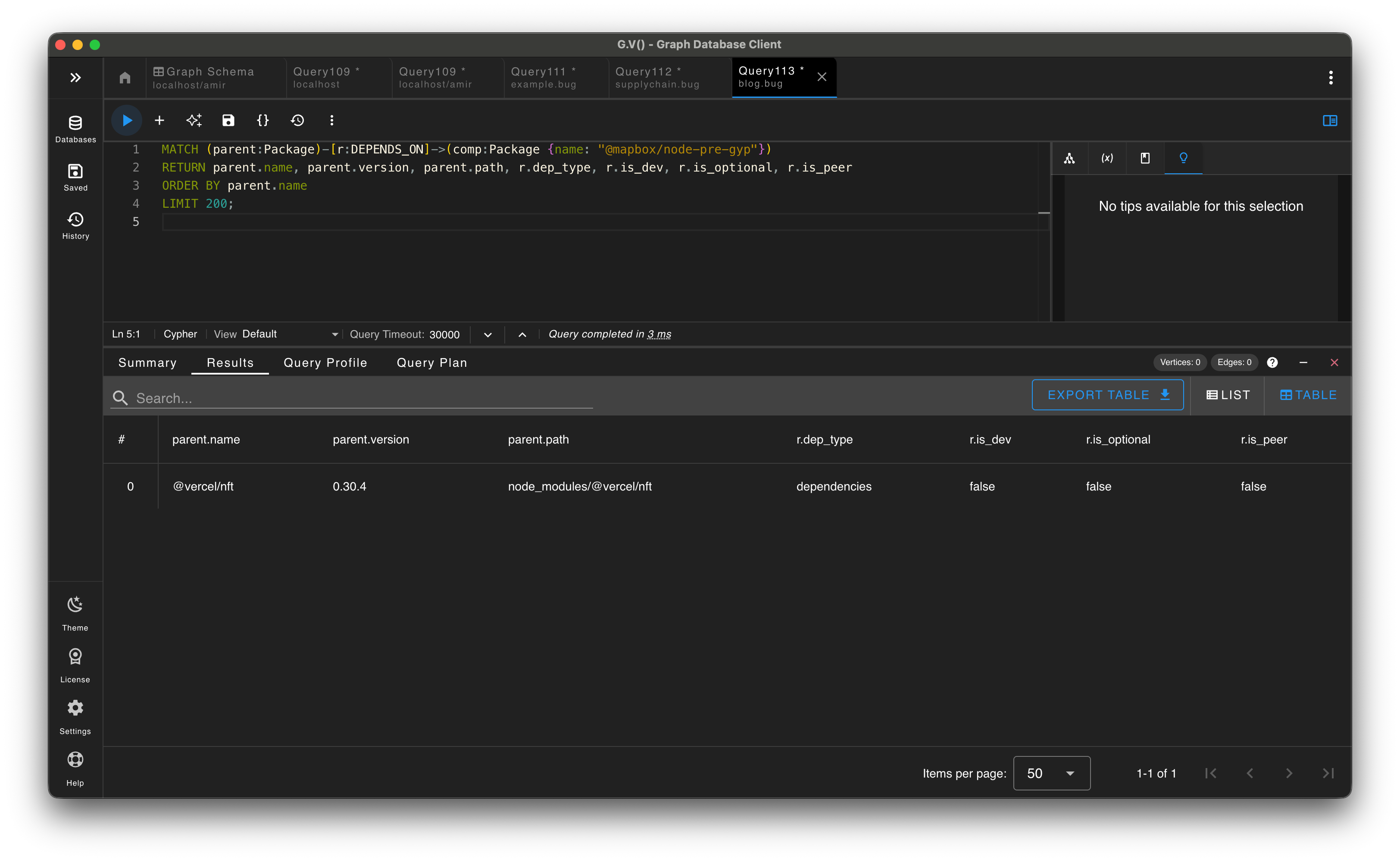
For triage, it helps to answer simple questions fast: do we have a package, where does it appear, and what might be impacted?
Key Takeaways from the Experiment
- Variable-length path patterns require a practical upper bound to avoid performance degradation.
- CSV import is fast and straightforward, enabling rapid iteration.
- At the scale of a typical
package-lock.json(thousands of nodes/edges), query performance remains excellent. - G.V() provides immediate visualization and exploration capabilities for LadybugDB-loaded graphs.
This approach complements (but does not replace) standard tools such as npm ls, npm why, OSV-Scanner, and Dependabot for routine dependency checks.